

SHERLOCKED - Text Generator Part 1
“There is nothing more deceptive than an obvious fact.” ― Arthur Conan Doyle, The Boscombe Valley Mystery. Feel Sir Arthur’s Work was’nt just enough for you ? Let’s generate our own ;).
This is episode 1 of the series ‘SHERLOCKED’, in this part we will learn to code from scratch and implement a simple text generator to write Sherlock Holmes using LSTMs. The source code for this and the notebook used for this tutorial are available in my github repository.
Reader’s Note To enable people who might be new to this field and dont understand common (or difficult) words commonly used in NLP like LSTMs or Bi-directionality, I have a feature : Dictionary, where I mark all such instances with superscripts and they are referenced at the bottom, linked to the dictionary where I reference related articles to give a formal understanding. In case you want to add to them you can make your pulls to my repository This feature is under construction
Unsupervised Text Generation
Text Generation is a type of Language Modelling problem. Language Modelling is the core problem for a number of of natural language processing tasks, in unsupervised learning you process your text to a squence of tokens and then encode them to integers so that it can be fed to a neural network. You train these sequences to predict the correct target, in our case the word following a sequence, there are some approaches where the target can be n_grams as well . There are two broad category of these models : Character Based Models and Word Based Models
In character based models you select n-character grams to predict the coming character/characters your domain and range both are the set of characters used for training, this is a simpler task as we have a smaller domain therefore enough combinations for training, but the model fails to generate more context and is prone to grammatical errors
In word based models you treat your vocabulary to be the universal set of values your domain and range belong to therefore the model does’nt encounter every possible combination, but will never have spell errors, and grab better and more sensible predictions for longer sequences. The major drawback of word based models are OOV (Out Of Vocabulary) Words, since they were never a part of your training domain it will throw an error.
Our Model
We will be using Word based LSTMs for this part, our objective is to make an Object Factory of Authors, in this case Arthur Conan Doyle, the writer of the famous fiction Sherlock Holmes. Our final model will consist of an Author and his Pen, Brain, and Data Along with the flags which will be the genome of our Author, ie the values that distinguish the Author objects. which in turn will consist of further functions which we will work with to assimilate our Author and to maintain all our stacked LSTMs.
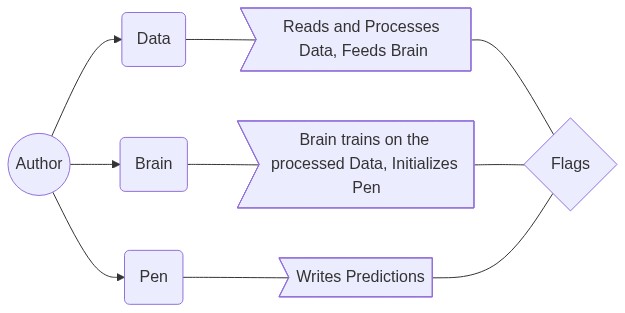
Flags
When you have models that can take more than a few hundred lines of code it is always a bad idea to not have them as objects of classes, therefore we will build classes for this model, and to have consistency throughout the model instead of passing variables to each class/object we will create a python namespace/dictionary. The namespace we will begin can be initialized this way :
Data
Extraction
All the data has been collected from sherlock-holm.es. You can collect this data in python :
Exploration and Preprocessing
Since this is a text generation task you should not make unnecesary changes in the text, common preprocessing techniques in NLP like Stemming, removal of stopwords are unnecesary here because we have to generate the text which syntactically and semantically replicates the original text.
The consistency of the characters is already very neat we will replace all ’ (styled quotation mark) with the ‘ (ascii) and delete all other special characters, as the total contribution to the text is ~2.86e-5, we have removed unnecessary spaces and newlines that are a part of the book due to its printing, Change of page, alignment of text etc., Also we will strip the text of its metadata, Chapter names, table of contents etc. by splitting them according to their chapters and selecting only the text present in the chapters.
Gear up now we are all set to start coding our Author’s Data or Memory component !
Data Class
We have encoded the text with integers, and created sequences of words and made batches for training, I am using google collaboratory for training with a GPU, so this is the memory constraint.
Brain
Now that we have our data object it is about time we start training the Author by initializing his brain!
The Data Class
Congrats you have made your own Artificial Arthur Conan Doyle, Now let’s see how to make him smarter in the next part !