

FlaiReddit
Published:
FlaiReddit is a text classification webapp deployed on Heroku which detects the ‘flair’ tags of a Reddit Post from the subreddit r/india. This project consists all major steps important to any applied machine learning pipeline - Data Collection, Processing, Optimized Classifier, Deployment.
Data Collection - Web Scraper
We will use the pushlift.io API instead to make calls and extract JSON packages. The data extractor extracts posts from a wide time period to eliminate the Bias towards some hot topics.
- You can save and load your progress at checkpoints too (especially useful for online collection and storage),
- Approximately 600 posts can be extracted per second, however as a result of the moderation of the subreddit only 20% of the data is actually available.
- All logs are made in crawler.log, warnings are displayed.
- To optimize space removed, empty flairs are removed batch wise.
Usage
from modules.crawler import *
start_time = #Enter the unix timestamp of date since when scraping should begin
end_time= #Enter the unix timestamp of date since when scraping should end
scraper = Crawler(size=1000, difference=12, sleep=0.5, start=start_time)
while(scraper.current > end time):
red.query() #Query the database
red.dump() #Dump the stats and csv
A commited notebook is available at kaggle
Exploratory Data Analysis
Extensive analysis has been done, important words are visualized through WordClouds, in depth explanation of these and preprocessing is present in my Notebook
A baseline model from BOW is also implemented at the end.
Training the Model [BERT, TFIDF]
We set the seed for reproducibility and use BERT - uncased, base, freezing all layes apart from the last layer and the weights are saved for easier inference at :
Model Summary [Inference Time]:
| Model | Micro-F1 | Macro-F1 | Inference |
|---|---|---|---|
| TFIDF Combined | 0.51 | 0.50 | 331 Samples/s |
| BERT | 0.60 | 0.59 | 2.37 Samples/s |
| TFIDF | 0.49 | 0.48 | 273 Samples/s |
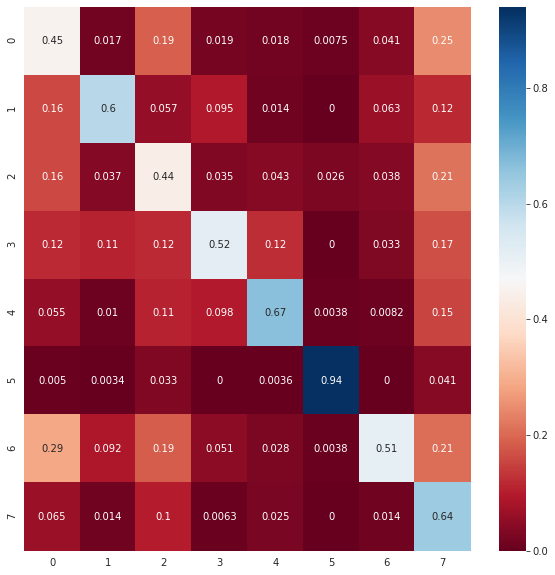
The confusion matrix is plotted below
WebApp - Flask TFIDF
- For the web app we have used the TFIDF model keeping the CPU Rate and Memory Usage in mind [BERT BASE has 114 M parameters].
- The app is created on flask, the root view is a simple webpage where you can enter the weblink and the predicted flair is displayed.
- The other end point is \auto, to which a post request is sent and the prediction json is sent back.
- Logs and Error pages will be enabled in a future update.
- The colour theme used is taken from reddit’s own theme :)
Auto Endpoint
>>> import requests
>>> with open('file.txt','wb') as f:
f.write(b"r/india post urls")
>>> base_url = "https://flaireddittest.herokuapp.com" #http://127.0.0.1:5000/ if local
>>> url = f"{base_url}/auto"
>>> files = {'upload_file': open('file.txt','rb')}
>>> r = requests.post(url, files=files)
>>> r
<Response [200]>
>>> r.json()
{"post_url" : 'predicted tag'}
This way you can use the app from a user/developer’s perspective —
HEROKU DEPLOYMENT
- Finally the web application is deployed on Heroku and is available at FlaiRedditTest
- You can visit the project’s github repository at : FlaiReddit
- You can check the deployed webapp at : FlaiReddit Heroku


